This comprehensive guide explains the underlying technology behind text comparison tools, including diff algorithms, line-based vs character-based approaches, the role of whitespace handling, performance considerations, and practical best practices for accurate results.
How text comparison works
Text comparison, often referred to as a diff operation, is the process of identifying differences between two sequences of characters or lines. Full-featured diff tools often use algorithms such as LCS or Myers diff to align inserted and removed sections. This browser tool uses a lighter line-position comparison, which is fast for quick checks but does not try to realign large inserted or deleted blocks.
According to the Wikipedia article on the diff utility, the original diff program was developed at Bell Labs in the early 1970s and has since become a fundamental tool in software development. Modern web-based tools can run comparison logic in JavaScript, allowing this page to compare text in the browser without intentionally submitting your entered content to a comparison server.
Follow these steps to compare two texts efficiently:
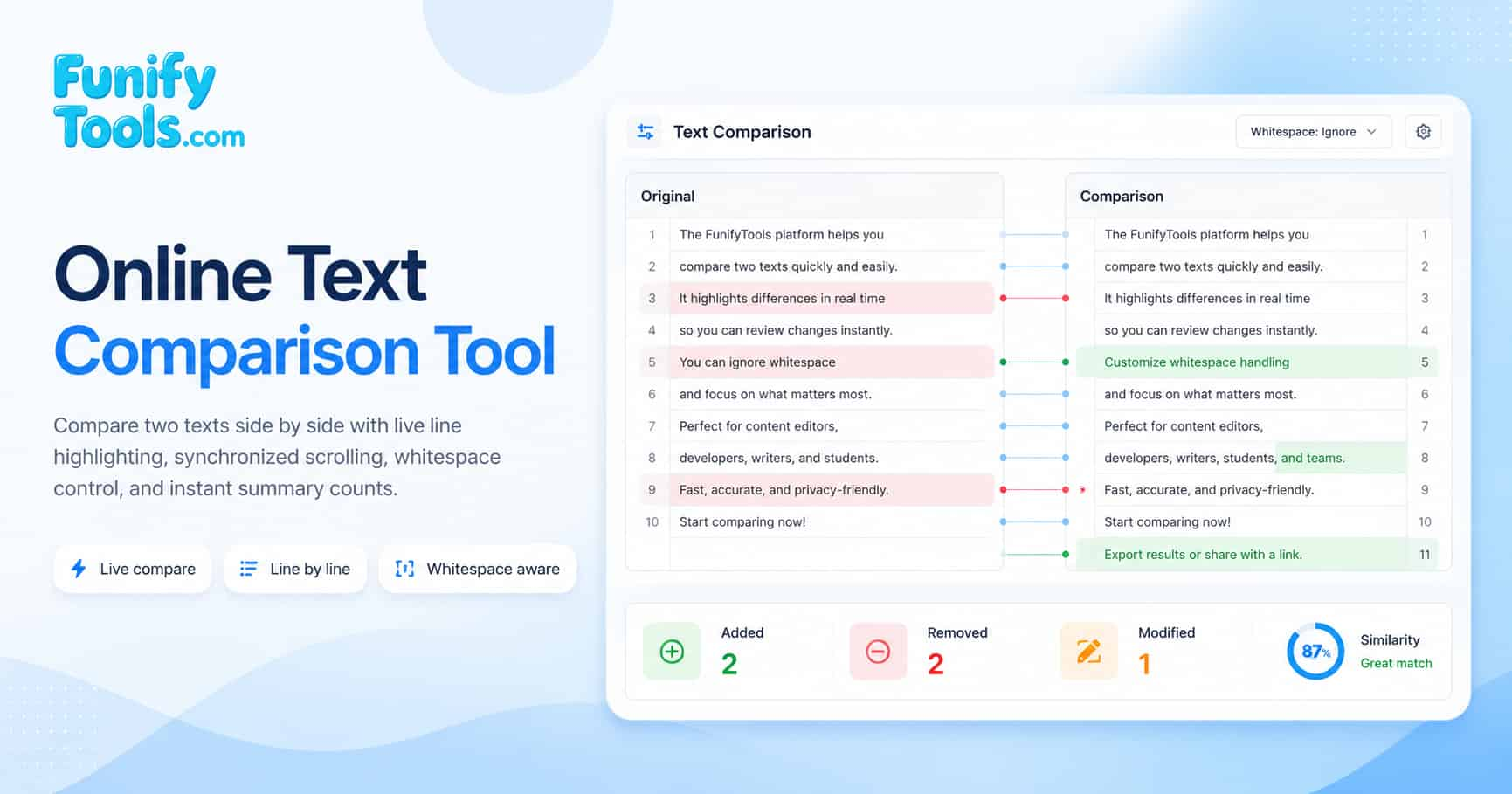
- Input Original Text: Enter or paste the first text into the left editor. This serves as the baseline for comparison.
- Input Comparison Text: Enter or paste the second text into the right editor. The tool compares both inputs line by line automatically.
- View Differences: Differing lines are highlighted in the comparison editor with pink emphasis and a gutter marker for quick identification.
- Ignore Whitespace: Enable the checkbox when leading and trailing spaces should not count as meaningful changes.
- Use Clear Controls: You can clear the left editor, the right editor, or both editors with the built-in action buttons.
- Review Summary: The result preview updates total differences, added lines, removed lines, and modified lines in real time.
- Inspect Long Texts: Scroll either editor and the other one follows vertically for easier side-by-side review of lengthy documents.
Diff algorithms explained
Understanding the algorithms behind text comparison helps you interpret results more accurately. Three major algorithmic approaches are used in modern diff tools, each with distinct characteristics.
| Algorithm | Time Complexity | Best suited for | Notable implementations |
|---|---|---|---|
| Myers Diff | O(ND) where N = total lines, D = number of differences | General-purpose text comparison with minimal edit script | Google diff-match-patch, Git |
| Hunt-McIlroy | O((N+R) log N) where R = number of matching pairs | Long documents with many identical sections | Original Unix diff, BSD diff |
| LCS (Dynamic Programming) | O(N × M) where N, M = lengths of sequences | Small to medium texts with predictable structure | Educational tools, JavaScript diff libraries |
The Myers diff algorithm, published by Eugene W. Myers in 1986, is widely regarded as the most efficient for producing the shortest edit script. As documented in the original ACM paper "An O(ND) Difference Algorithm and Its Variations", this algorithm guarantees the minimum number of insertions and deletions needed to transform one sequence into another.
Line vs character comparison
Text comparison tools can operate at different granularity levels. Understanding the trade-offs helps you choose the right approach for your specific use case.
| Aspect | Line-based comparison | Character-based comparison |
|---|---|---|
| Granularity | Entire lines are compared as atomic units | Individual characters within lines are compared |
| Performance | Faster for large documents (fewer elements to compare) | Slower, especially for long lines (more elements to process) |
| Best for | Code, configuration files, logs, structured data | Prose, natural language text, detailed editing |
| False positives | Fewer; only whole-line changes are flagged | More; single character differences are highlighted |
| Readability | Higher; changes are grouped by line | Lower; inline changes can be visually noisy |
This tool uses a line-based, position-by-position comparison because it offers a clear and fast overview for code snippets, logs, configuration files, and article drafts. For realignment across inserted or deleted blocks, or for granular character-level comparison, tools like those listed on Wikipedia's file comparison tools page may be more appropriate.
Whitespace impact on comparison
Whitespace handling is one of the most important configuration options in any text comparison tool. Different workflows require different whitespace sensitivity, and understanding this can dramatically improve the accuracy of your results.
| Scenario | Whitespace mode off (exact) | Whitespace mode on (trimmed) | Recommended |
|---|---|---|---|
| Code indentation changed | Flagged as modified | Ignored (treated as identical) | Whitespace on if only logic matters |
| Trailing spaces added/removed | Flagged as modified | Ignored | Whitespace on (trailing spaces are rarely meaningful) |
| Markdown or plain text formatting | Flagged as modified | Ignored | Whitespace off if formatting changes are intentional |
| CSV/TSV data with padded internal columns | Flagged as modified | Still flagged if internal spacing changes | Normalize delimiters or spacing before comparing |
| JSON/XML with pretty-print | Flagged as modified | Only leading and trailing whitespace is ignored | Format both versions consistently before comparing |
As explained in the GNU Diffutils manual, whitespace options have been a standard feature of diff tools since the early days of Unix. This page applies a limited version of that idea by trimming each line before comparison, which is helpful when leading or trailing spacing is cosmetic rather than meaningful.
Use cases and applications
Text comparison serves a wide range of professional and personal applications. The ability to quickly identify differences between two versions of text is fundamental to many workflows.
Software development and version control
- Compare code changes between Git commits or branches before merging.
- Review configuration file differences across environments (development, staging, production).
- Debug by comparing log outputs from different runs to identify anomalies.
- Validate refactored code against the original to ensure no unintended changes.
Content creation and publishing
- Track editorial revisions in articles, blog posts, and manuscripts.
- Compare translations against source text to verify completeness and accuracy.
- Review copy changes before publishing to catch unintended modifications.
- Compare SEO metadata (titles, descriptions) across page versions.
Academic and legal work
- Compare draft versions of research papers or theses.
- Review contract amendments and legal document revisions.
- Check whether quoted passages or assignment drafts match provided source excerpts.
- Verify citation accuracy across document versions.
Data processing and quality assurance
- Compare CSV exports or database dumps to verify data integrity after migration.
- Validate API response changes between software versions.
- Review HTML or XML output changes after template modifications.
- Compare generated reports against expected output formats.
Performance and scalability
When comparing large texts, understanding performance characteristics helps you plan your workflow effectively. The tool's line-based approach offers significant advantages for documents up to several thousand lines.
Factors affecting comparison speed
- Total line count: The primary factor. Each additional line increases comparison time linearly in the best case.
- Number of differences: More differences require more processing to track and highlight.
- Line length: Very long lines (thousands of characters) can slow down the comparison, especially when whitespace trimming is enabled.
- Browser memory: The CodeMirror editors and highlight markers consume memory proportional to document size.
Recommended limits for optimal performance
- Up to 1,000 lines: Instant comparison with no noticeable delay.
- 1,000 to 5,000 lines: Slight delay on initial comparison; real-time updates remain smooth.
- 5,000 to 10,000 lines: Noticeable delay on each edit; consider comparing in sections.
- Over 10,000 lines: Significant performance impact; use desktop diff tools for large-scale work.
Known limitations
While this text comparison tool is useful for fast browser-based inspection, it has practical boundaries that users should understand before relying on it for critical workflows.
- Scope: Designed exclusively for plain text input. Images, binary files, and rich media are not supported.
- Performance ceiling: Very large texts (over 10,000 lines) can cause noticeable browser rendering lag and editor interaction delays.
- Granularity: The tool compares lines by position and does not evaluate semantic meaning.
- No insertion alignment: Added or removed lines can make following lines appear modified until the two texts line up again.
- Formatting sensitivity: Complex formatting changes (e.g., whitespace restructuring in XML) can produce misleading visual results.
- Browser dependency: The page relies on JavaScript (CodeMirror library) and requires a modern browser with adequate memory allocation.
- No persistent storage: Text entered into the editors is not saved between sessions. Users should maintain their own backups of important content.
Best practices for accurate text comparison
Following these best practices will help you get the most reliable results from any text comparison tool, whether browser-based or desktop.
Pre-comparison preparation
- Normalize line endings (CRLF vs LF) before comparing, as inconsistent line endings can cause false positives.
- Remove trailing whitespace from both texts if whitespace differences are not meaningful to your review.
- Sort or organize both texts in a consistent order when comparing structured data like lists or inventories.
- Break extremely large documents into logical sections (e.g., chapters, modules, functions) for focused comparison.
During comparison
- Start with whitespace mode enabled for an initial overview, then disable it for detailed review if formatting changes matter.
- Use the summary counts as a triage tool: high difference counts warrant closer inspection of individual lines.
- Compare in stages when dealing with multiple revisions: compare v1 vs v2, then v2 vs v3, rather than v1 vs v3 directly.
- Document the whitespace setting used for each comparison session so results can be reproduced later.
Post-comparison validation
- Manually verify a representative sample of highlighted lines to confirm the comparison logic is working as expected.
- Cross-reference comparison results with version control history (e.g., Git log) when reviewing code changes.
- For critical documents, have a second reviewer independently verify the differences using their own comparison session.
- Export or screenshot the comparison results for documentation and audit trails.
Results are for educational and testing purposes only. Actual comparison outcomes depend on the entered text, line breaks, active whitespace setting, and browser environment.