This comprehensive guide explains how text analysis works under the hood, how the page counts characters and words across multiple languages, how to interpret writing quality metrics, and how to use the results effectively for writing, SEO, education, localization, and development workflows. Understanding these fundamentals helps you get the most out of the online text analyzer tool and make informed decisions about your content.
How to use the text analyzer
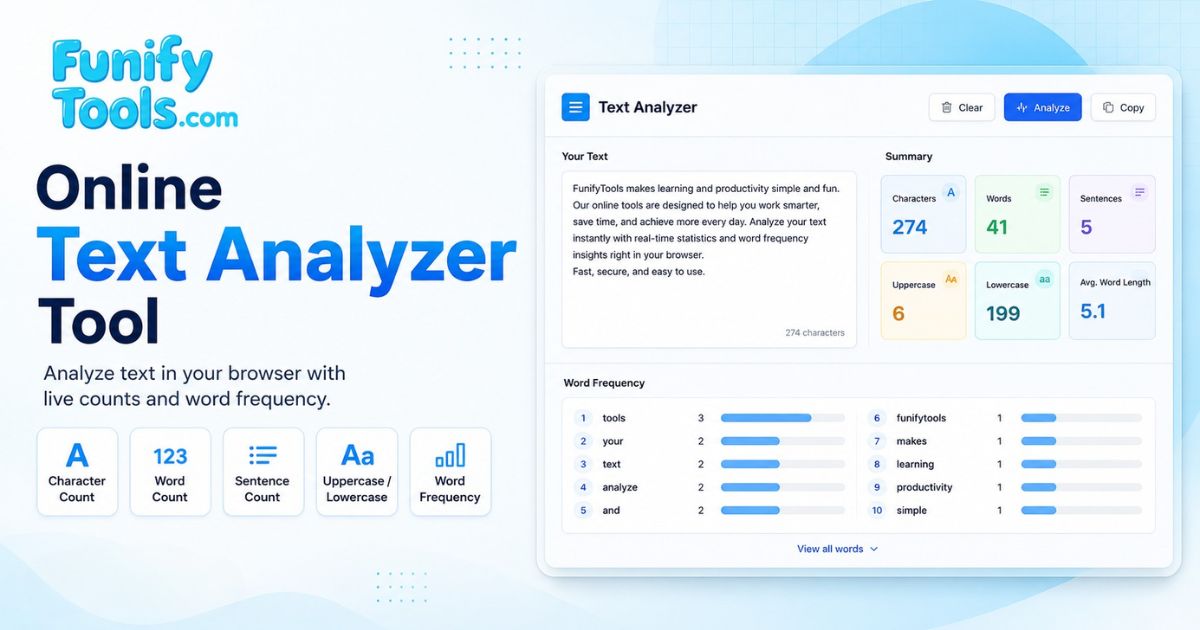
The text analyzer is designed for instant feedback. As you type or paste content into the editor, every metric updates automatically without requiring a button click or page reload. This real-time behavior makes it suitable for quick checks during writing sessions, content editing, translation reviews, and educational exercises. The tool processes all input entirely on your device, so your text never leaves your browser.
- Enter text: Input your text in the editor. This can be an essay, article, code snippet, blog post, study note, social media caption, email draft, or any other content that needs analysis.
- View real-time results: As you type, the page automatically updates metrics such as character count, word count, sentence count, and writing quality indicators in the result panel.
- Review detailed metrics: Explore total characters, no space counts, no line break counts, uppercase and lowercase totals, and word frequency rankings sorted by occurrence.
- Export results: Copy the summary or the full text when you need to move the content into reports, documentation, spreadsheets, or another workflow.
- Clear the editor: Use the clear action when you want to reset the editor and all counts for a new analysis session.
Technical principles of text analysis
Text analysis tools rely on character encoding, Unicode text representation, word boundary detection, and regular expressions. Understanding these principles helps you interpret results more accurately and avoid common pitfalls when analyzing multilingual or technically formatted content.
Character encoding and Unicode standards
Modern text analysis depends on the Unicode standard, which assigns a unique code point to every character across all writing systems. JavaScript String.length counts UTF-16 code units rather than visible characters, so some emoji, CJK characters, and supplementary symbols may be counted as two units. For example, the emoji 😀 (U+1F600) is represented as a surrogate pair in UTF-16 and contributes 2 to the length. The text analyzer exposes this browser-based count alongside space and line break variants, so you can choose the measurement that matches your use case.
Word boundary detection
Detecting word boundaries in multilingual text is one of the most technically challenging aspects of text analysis. This tool uses Unicode property escapes (\p{L}, \p{M}, \p{N}) to identify letter sequences, combining marks, and number tokens across scripts such as Latin, Hangul, Han, Hiragana, Katakana, Arabic, Devanagari, and Cyrillic. A word is defined as a contiguous sequence of Unicode letter, mark, or number characters, separated by whitespace or punctuation. This approach ensures that scripts without explicit spacing, such as Chinese and Japanese, are included in the count instead of being ignored by a basic English-only pattern, although semantic word segmentation may still differ by language.
Client-side processing architecture
All analysis runs entirely in the browser with vanilla JavaScript and CodeMirror for the editor. The page listens to editor change events and recalculates the visible summary on every keystroke. No text is intentionally sent to any external server, which means your content stays private during normal use and the analysis can remain responsive after the page assets are loaded. This architecture also keeps the tool fast for moderate text sizes, though very large documents may still affect responsiveness depending on your device.
Counting methods comparison
Different counting methods serve different purposes. The table below explains how each method works and when to use it. Choosing the right method prevents confusion when comparing results across different tools or platforms.
| Method | Counting rule | Example: hello world | Use case |
|---|---|---|---|
| Total characters | All characters including spaces and punctuation | 11 | General length measurement |
| Without spaces | Removes whitespace characters | 10 | Content-only volume estimation |
| Without line breaks | Removes CR and LF line breaks | 11 | Single-line equivalent length |
| UTF-16 code units | JavaScript String.length behavior | 11 | Low-level browser measurement |
For most writing tasks, total characters or characters without spaces provide the most practical measurements. The UTF-16 code unit count is mainly useful for developers who need to match JavaScript runtime behavior or enforce input length limits in web forms.
Unicode and word boundaries
Word boundary detection is one of the most technically challenging aspects of text analysis. This page uses Unicode property escapes so that non-Latin scripts are not ignored by a basic English-only pattern. The table below demonstrates how the same parsing logic handles different writing systems.
| Script | Example text | Parsed words | Word count |
|---|---|---|---|
| Latin | The quick brown fox | The, quick, brown, fox | 4 |
| Hangul | 안녕하세요 반갑습니다 | 안녕하세요, 반갑습니다 | 2 |
| Han | 中文字符统计 | 中文字符统计 | 1 |
| Mixed scripts | Hello 한글 123 | Hello, 한글, 123 | 3 |
Mixed-script content is common in modern communication, academic writing, and localization work. The text analyzer handles each script within the same word boundary logic, so a sentence containing Latin, Hangul, and numeric tokens is counted consistently within the page's parser.
Writing quality metrics
Beyond basic character and word counts, the text analyzer provides writing quality indicators that help you assess readability, sentence variety, and vocabulary usage. These metrics are especially useful for content writers, editors, students, and non-native speakers who want to improve the clarity and structure of their writing.
Readability and sentence length
The average sentence length, calculated as the total word count divided by the number of sentences, is a practical readability indicator. Short sentences averaging 15 to 20 words are generally easier to read, while longer averages above 25 words may indicate complex or run-on structures. The analyzer reports word and sentence totals, so you can estimate average sentence length and identify passages that may benefit from restructuring.
Case usage analysis
The uppercase and lowercase character counts reveal how much of your text uses capital letters. A high uppercase ratio may indicate excessive use of acronyms, headings written in all caps, or SHOUTING in informal communication. The analyzer reports both counts separately so you can review case balance in your content.
Word frequency and vocabulary diversity
The word frequency ranking lists every unique word found in the text along with how many times it appears. This feature helps you identify overused terms, check keyword density for SEO, and improve vocabulary variety. A text that repeats the same word many times within a short passage may benefit from synonym replacement. The table below shows a typical frequency output structure.
| Rank | Word | Frequency | Observation |
|---|---|---|---|
| 1 | the | 12 | Common article, expected at top |
| 2 | text | 7 | Topic word, natural frequency |
| 3 | analysis | 5 | Topic word, natural frequency |
| 4 | word | 4 | Common measurement term |
| 5 | count | 4 | Common measurement term |
Character type distribution
Understanding how many characters are letters, digits, whitespace, and punctuation helps in specialized formatting tasks such as preparing data for database fields, API payloads, or print layouts. The table below shows a typical distribution breakdown.
| Character type | Count | Percentage | Notes |
|---|---|---|---|
| Letters | 320 | 72% | Core content characters |
| Digits | 18 | 4% | Numbers and numerical data |
| Whitespace | 85 | 19% | Spaces, tabs, line breaks |
| Punctuation and symbols | 22 | 5% | Periods, commas, quotes, dashes |
High whitespace ratios often indicate excessive formatting or unnecessary line breaks, while a low punctuation ratio may suggest run-on sentences or missing structural markers. Use these indicators together with the sentence count to evaluate writing quality holistically.
Practical applications of text analysis
Writing and editing
- Monitor word counts for essays, articles, or manuscripts to meet submission rules and platform limits.
- Review sentence volume and average length tendencies to improve readability and flow.
- Identify repeated words through the frequency ranking and improve vocabulary variation.
- Track character counts for headlines, meta descriptions, and social media posts with strict length constraints.
SEO and content marketing
- Analyze keyword repetition when optimizing content for search visibility and topical relevance.
- Check whether a page reaches a target word count range for comprehensive coverage.
- Estimate character counts for title tags, meta descriptions, and snippet text.
- Use the word frequency list to balance primary and secondary keyword usage naturally.
Software development and localization
- Count characters in source snippets, configuration files, or structured output for validation.
- Check UI strings when length limits matter for button labels, tooltips, and form fields.
- Compare source and translated text sizes for approximate layout balance in internationalization.
- Verify line break and whitespace counts in formatted output such as CSV, JSON, or markdown.
Education and language learning
- Analyze student writing for sentence variety, word repetition, and overall length.
- Compare vocabulary usage across drafts to track improvement in lexical diversity.
- Practice concise writing by monitoring character and word counts against a target.
- Review case usage and punctuation patterns in formal and informal writing exercises.
Limitations and best practices
- Client side processing: Very large texts exceeding several hundred thousand characters can slow the browser or reduce responsiveness. Split large documents into smaller sections for better performance.
- Sentence detection: Informal text without clear punctuation, such as chat logs, bullet lists, or poetry, may reduce sentence detection accuracy.
- Browser compatibility: Unicode property escapes require a modern browser that supports ECMAScript 2018 or later. Older browsers may fall back to less accurate word boundary detection.
- No semantic analysis: Character and word counts do not explain meaning, sentiment, tone, or context. For semantic understanding, pair this tool with a dedicated language analysis platform.
- Word frequency limitations: The frequency list counts exact word forms and does not lemmatize or stem. For example, "run" and "running" are counted as separate entries.
Best practices for accurate results
- Normalize text encoding to UTF-8 before pasting content from external sources such as word processors or PDF files.
- Remove unnecessary formatting noise if the goal is content measurement rather than layout review.
- Split very large texts into smaller sections for better performance and easier review of frequency data.
- Prefer plain text over rich text when you want predictable and repeatable counts across different tools.
- Use the word frequency list to reduce repetitive terms before publishing or submitting content.
- Cross-check sentence counts with a manual review when analyzing highly structured or fragmented content.
Text statistics reference table
This reference table summarizes the metrics shown by the text analyzer, plus one derived value you can calculate from the visible word and sentence totals. Use it as a quick lookup when reviewing your analysis results.
| Metric | Definition | Interpretation |
|---|---|---|
| Total characters | All characters including spaces, punctuation, and line breaks | General measure of content length |
| Characters without spaces | Total characters minus all whitespace | Content-only volume for density estimation |
| Characters without line breaks | Total characters minus CR and LF characters | Single-line equivalent length for copy fitting |
| Uppercase characters | Count of uppercase letter characters | High values may indicate excessive capitalization |
| Lowercase characters | Count of lowercase letter characters | Normal writing case, should dominate in prose |
| Total words | Number of word tokens detected by Unicode-aware parsing | Primary volume metric for writing and SEO |
| Total sentences | Number of sentences detected by punctuation-based matching | Can be used with word count to estimate average sentence length |
| Estimated average sentence length | Total words divided by total sentences | 15-20 words is readable; above 25 may be complex |
| Word frequency | Ranked list of unique words with occurrence counts | Identifies overused terms and keyword density |
Platform character and word limits reference
Different online platforms enforce specific character and word limits for posts, descriptions, and metadata. This reference table helps you check whether your content meets platform requirements before publishing.
| Platform | Field | Limit | Notes |
|---|---|---|---|
| Title tag | ~60 characters | Display truncation varies; keep under 60 for best visibility | |
| Meta description | ~160 characters | May display up to 320 in some results | |
| Twitter / X | Post | 280 characters | Counts CJK characters differently |
| Caption | 2,200 characters | First 125 visible in feed without expansion | |
| Post | 63,206 characters | Practical limit much lower for engagement | |
| Post | 3,000 characters | Long posts may see reduced reach | |
| YouTube | Description | 5,000 characters | First 2-3 lines visible in collapsed view |
| SMS | Single message | 160 characters | GSM-7 encoding; Unicode reduces to 70 |
Use the text analyzer to pre-check your content against these limits before publishing. The characters without line breaks metric is especially useful for single-line fields such as title tags and meta descriptions.
Readability scale and sentence length guide
Average sentence length is one of the simplest readability indicators. This table maps average sentence length ranges to readability levels and provides guidance for different content types.
| Avg. sentence length | Readability level | Suitable for |
|---|---|---|
| 5-10 words | Very easy | Children's content, headlines, captions |
| 11-15 words | Easy | General web content, blog posts, social media |
| 16-20 words | Moderate | News articles, educational materials, business writing |
| 21-25 words | Fairly difficult | Academic papers, technical documentation, reports |
| 26-30 words | Difficult | Legal documents, scholarly journals, complex analysis |
| 30+ words | Very difficult | Specialized research, dense technical specifications |
For most online content, targeting an average sentence length of 15 to 20 words provides a good balance between clarity and depth. Use the sentence count and word count from the text analyzer to estimate where your content falls on this scale.