Understanding text encoding fundamentals
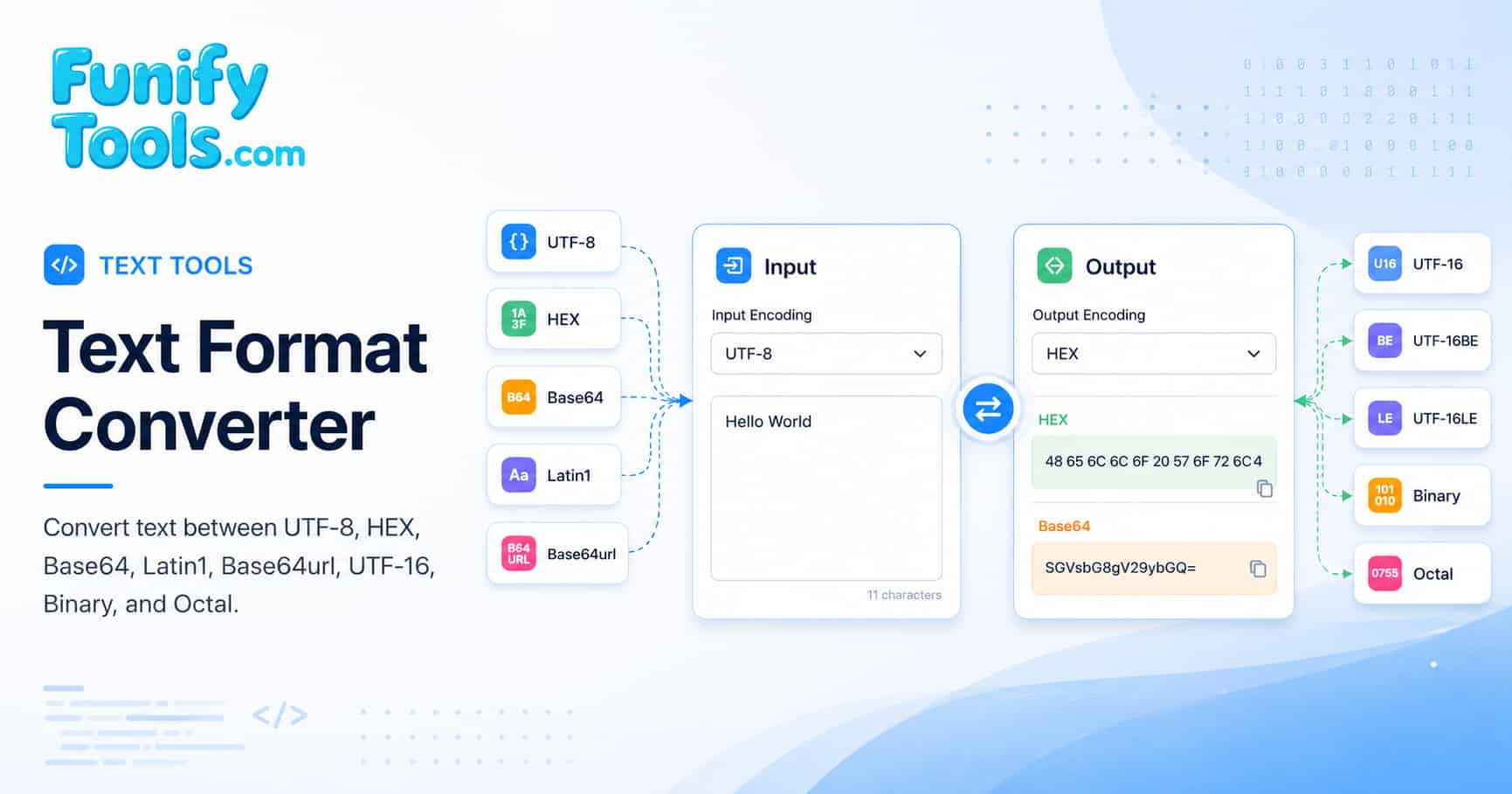
Text encoding is the process of converting human-readable characters into a specific byte representation that computers can store, transmit, and process reliably. According to the W3C character encoding standards, choosing the correct encoding is essential for data interoperability across the web. The Unicode Consortium maintains the authoritative specification for character encoding -you can explore the Unicode standard reference for the complete technical details behind each encoding scheme.
Every encoding scheme maps characters to byte sequences differently. UTF-8 uses a variable-width approach where the first 128 code points (U+0000 to U+007F) occupy a single byte and match ASCII exactly, while higher code points require two to four bytes. UTF-16 uses either two or four bytes per code point, and encodings like Base64 transform binary data into a 64-character ASCII subset for safe transmission over text-based protocols. The IETF RFC 3629 specification formally defines UTF-8, and the IETF RFC 4648 standard governs Base64 and Base64url encoding rules.
When you paste a HEX string like 48656C6C6F into this converter, the tool interprets each pair of hexadecimal digits as one byte (0x48, 0x65, 0x6C, 0x6C, 0x6F) and decodes them into the ASCII characters "Hello". The same principle applies to Binary (8 bits per character), Octal (3 digits per byte), and Base64 (4 characters per 3 bytes). Understanding these structural differences helps you debug data transmission issues, inspect API payloads, and work confidently with cross-platform data formats. For a deep technical dive, refer to the MDN Web Docs TextEncoder and TextDecoder API reference.
Encoding table comparison
The table below summarizes the key characteristics of each encoding format supported by this converter. Understanding these properties helps you select the right encoding for your specific use case.
| Encoding | Byte width | Character set | Common use |
|---|---|---|---|
| UTF-8 | 1-4 bytes | All Unicode (1,112,064 code points) | Web pages, JSON, HTML, XML, email |
| UTF-16 | 2 or 4 bytes | All Unicode (surrogate pairs for >U+FFFF) | JavaScript internals, Java, .NET, Windows APIs |
| Latin1 (ISO-8859-1) | 1 byte | 256 characters (U+0000 to U+00FF) | Legacy databases, Western European text |
| HEX (Base16) | 2 hex digits per byte | 0-9, A-F | Memory dumps, color codes, cryptography, debugging |
| Base64 | 4 chars per 3 bytes (~33% overhead) | A-Z, a-z, 0-9, +, /, = | Email attachments (MIME), data URIs, JWT tokens |
| Base64url | 4 chars per 3 bytes (~33% overhead) | A-Z, a-z, 0-9, -, _ | URL-safe tokens, OAuth, JWT, web APIs |
| Binary | 8 bits per byte | 0, 1 | Low-level debugging, bitwise operations, education |
| Octal | 3 octal digits per byte | 0-9 | Unix file permissions, legacy systems |
Common use cases for each encoding
Each encoding format serves specific purposes in real-world software development. The table below maps each format to its most frequent applications, helping you decide which encoding to choose for your workflow.
| Encoding | Industry | Example scenario |
|---|---|---|
| UTF-8 | Web development | Serving multilingual HTML pages with |
| HEX | Cybersecurity | Inspecting raw packet bytes in Wireshark or reading memory dumps |
| Base64 | API development | Embedding binary image data in JSON payloads as data URIs |
| Base64url | Authentication | Encoding JWT (JSON Web Token) header and payload segments |
| Latin1 | Database migration | Reading legacy MySQL tables using latin1 collation |
| UTF-16 | Desktop application development | Processing text in Windows .NET applications or Java strings |
| Binary | Computer science education | Teaching how ASCII characters map to their bit-level representation |
| Octal | System administration | Setting Unix file permissions with chmod 755 or 644 |
Byte length comparison table
When you convert the same text across different encodings, the output length can vary dramatically. The table below shows how the word "Hello" (5 characters) is represented in each format, demonstrating the storage impact of your encoding choice.
| Encoding | Output for "Hello" | Length |
|---|---|---|
| UTF-8 | Hello | 5 bytes |
| HEX | 48656C6C6F | 10 hex digits |
| Base64 | SGVsbG8= | 8 characters |
| Base64url | SGVsbG8 | 7 characters |
| Latin1 | Hello | 5 bytes |
| UTF-16 | H\x00e\x00l\x00l\x00o\x00 | 10 bytes |
| Binary | 0100100001100101011011000110110001101111 | 40 bits |
| Octal | 110145154154157 | 15 octal digits |
Troubleshooting encoding mismatches
Encoding mismatches are one of the most common sources of data corruption in software development. When you see garbled text, unexpected characters, or conversion errors, the root cause is almost always a mismatch between the actual encoding of the source data and the encoding you selected for interpretation. Here are practical troubleshooting strategies:
- Verify the source encoding first: Before converting, confirm how the original data was produced. API documentation, database schemas, and file headers often declare the encoding explicitly.
-
Test with a known pattern: If you have a sample value whose expected output you already know, convert it first to validate your encoding selection. For example, if you know "Hello" in HEX should be
48656C6C6F, use that as a sanity check. -
Check for BOM (Byte Order Mark): UTF-16 encoded files often begin with a BOM (
U+FEFF). If your HEX output starts withFFFEorFEFF, the byte order (endianness) may need adjustment between UTF-16BE and UTF-16LE. -
Inspect padding characters: Base64 output always uses
=padding when the input length is not a multiple of 3. Missing or extra padding characters indicate corrupted or truncated Base64 input. - Watch for whitespace and line breaks: Some encodings like Base64 may include newlines when generated by certain tools. Strip whitespace before converting if your output appears incomplete.
41). If this basic conversion fails, the encoding mismatch is fundamental and you should verify your input format selection before proceeding with larger payloads.